Column
コラム
AI Deep Dive【39】AI時代の「名前の整理術」 ―企業名や組織名のバラバラ問題を解決する方法―
2026.05.12
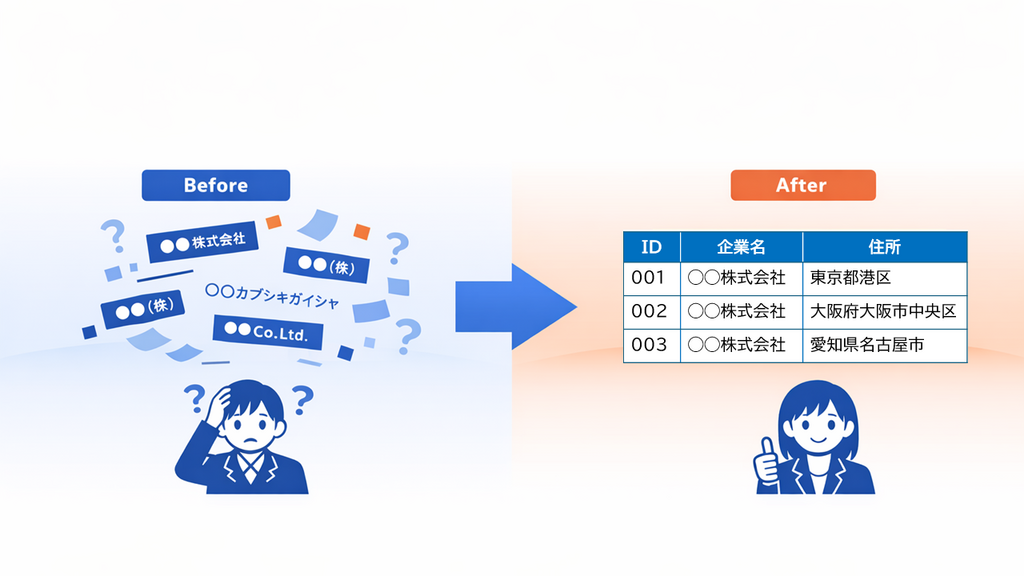
AIを業務に使っても、検索や集計の結果が安定しない―そんな悩みの原因は、企業名や組織名の表記ゆれにある場合が多くあります。
本稿では、企業名や組織名の表記ゆれを整理する「同義語辞書」を活用し、AIの出力や検索・集計を安定させるための考え方を紹介します。
はじめに:AI活用で生まれる違和感
最近、AIを使った業務が増えています。でも、「検索しても欲しい情報が出てこない」「集計した数字が合わない」といった悩みを感じたことはありませんか?こうした悩みの背景には、同じ会社であっても、データの中で別々の名前として扱われていることが少なくありません。たとえば、「NTT-AT」「NTTアドバンステクノロジ」「NTT Advanced Technology」など、同じ会社でも表記が違うと、AIやシステムは別の会社として扱ってしまいます。
こうした「バラバラの名前」をまとめて、同じものとして扱えるようにする作業が「名寄せ」です。AIや検索・集計の精度を安定させるためには、名前のゆれを同義語辞書として整理しておくことが不可欠です。
なお、ここでいう「同義語辞書」とは、言葉の意味を調べる辞書ではありません。企業名の正式名称や略称、英語表記など、表記の違いをまとめて「同じもの」として扱うための一覧表のようなものを指しています。
なぜ今、「名寄せ」が重要なのか
AIやデータ分析が進化しても、名前のゆれが整理されていなければ、技術の効果を十分に引き出すことはできません。
取引先情報の統合、社内文書の検索、顧客データの集計や分析といった業務では、名前のゆれが原因で、検索もれや集計ミスが発生することがあります。
AIは文章の意味理解を得意としますが、企業名のような固有名詞については、意味よりも文字の違いに影響を受けやすいという特性があります。この点が、実務上の違和感につながります。
名寄せを難しくする「ゆれの深さ」
名寄せが難しい理由は、単なる表記の違いだけでなく、その背後にある「ゆれの深さ」にあります。
同義語辞書というと、どうしても「どれくらいの件数があるか」に目が行きがちです。ただ、実務で効いてくるのは件数の多さというより、ゆれの深さです。ゆれの深さは、大きく分けて次の2つの要素で考えられます。
- 幅:表記のバリエーション
(略称、英語表記、記号や全角半角の違い、カナ表記、法人格の有無など) - 層:企業の関係性や時間軸を含む情報
(旧社名、合併等の統廃合の履歴、グループ関係、同名企業の分岐など)
たとえば、表記の種類(幅)が5通りあり、さらに履歴や関係性の違い(層)が3通りあるとすると、組み合わせとして考えるべきケースは「5×3=15」に増えます。この深さが大きくなるほど、単純な文字列処理だけでは対応が難しくなっていきます。
AIと同義語辞書を組み合わせる理由
「ゆれの深さ」を前提にすると、AIだけで名寄せを完結させるのは難しい場面があることが分かります。AIを使って名寄せを自動化する試みは増えていますが、略称が別企業と重なったり、企業関係が複雑な場合には、誤った判断が起こりやすくなります。そのため、AIにすべてを任せるのではなく、判断しやすい前提条件をあらかじめ整えておくことが重要になります。
名寄せで同義語辞書をどう捉えるか
上記の課題を踏まえ、名寄せに用いる同義語辞書の役割と考え方を整理します。
本稿では、名寄せに用いる「同義語辞書」を、「ミニ辞書」と「本体辞書」の2つに分けて考えます。両者は担う役割が異なるため、使い分けて考えることで、名寄せの設計や運用を整理しやすくなります。
なお、この「同義語辞書」は、すべてを一から作ることを前提としたものではありません。企業名や組織名を広くカバーする「本体辞書」は、既存の商用辞書や整備された辞書を利用することを想定しています。一方、「ミニ辞書」は、ユーザー自身が業務や用途に応じて作成し、AIのプロンプト(指示文)の中で調整・活用することを前提とした補助的な辞書です。
以降では、この二つの辞書をどのように使い分けるかを見ていきます。
名寄せの進め方と、同義語辞書の効きどころ
上記の考え方を前提に、実務の中で名寄せをどのような流れで進めると安定するのかを整理します。
入力:
業務データに含まれる、表記ゆれや略称、旧社名等が混在した企業名データ
(例:NTT-AT、NTT AT、NTT技術移転、・・・)
↓
AI+ミニ辞書:
あらかじめ定めた表記の扱い方を前提に、同一企業と思われる名称の「候補」を整理する。
(この段階では最終的な確定をしない)
↓
本体辞書:
正式名称や旧社名、統廃合の履歴など、事実に基づく情報を用いて、候補を企業IDに紐づけて確定する。
↓
出力:
同一企業ごとに整理された企業データ(企業ID、正式名称など)
(例:ID: C-01234567,正式名称:NTTアドバンステクノロジ株式会社)
名寄せの対象は、業務データに含まれる、表記ゆれや略称、旧社名などが混在した企業名データです。この段階では、どの名称が同じ企業を指しているのかは分かっていません。
まず、AI+ミニ辞書の工程で、AIにはあらかじめ「ここまでは同じ企業として扱ってよい」という表記の前提を与え、判断の土台をそろえたうえで、候補整理を行います。ここでは、あえて確定せず、整理にとどめます。
次に、本体辞書の工程で、整理された候補を、事実に基づく情報(正式名称や旧社名、統廃合の履歴など)と照合します。候補を企業IDに紐づけることで、同一性を確定します。
それでも、略称が複数の企業に該当するなど、機械的な判断だけでは割り切れないケースは残ります。例外についてのみ人が確認することで、名寄せ全体を現実的な負担で運用できます。
前提をそろえて候補を整理し、事実に基づく情報で確定し、例外だけを人が補う、という役割分担によって、名寄せは一時的な対応ではなく、継続的に使える仕組みとして安定していきます。
名寄せ以外での同義語辞書の効きどころ
最後に、ここまで紹介してきた考え方が、名寄せ以外の場面でもどのように活かせるかを見てみます。
ミニ辞書と本体辞書を分けて考えるこの設計は、名寄せだけでなく、AIを使ったさまざまな処理の前段で効果を発揮します。たとえば、RAG(検索拡張生成)を用いた文書検索では、検索クエリや文書側の表記がゆれているだけで、関連文書がヒットしなくなることがあります。
このとき、ミニ辞書で表記の型をそろえ、本体辞書で同一性を確定しておくことで、検索もれや回答のばらつきを抑えることができます。また、顧客データや取引先データを横断的に扱う場面でも、名寄せの結果が不安定だと、集計や分析のたびに確認作業が必要になります。
あらかじめ辞書を前提とした設計にしておくことで、「あとから直す」工程を減らし、運用をシンプルに保ちやすくなります。重要なのは、AIにすべてを判断させるのではなく、AIが判断しやすい前提をどこまで整えておくかです。ミニ辞書と本体辞書の役割分担は、そのための一つの実装しやすい指針と言えるでしょう。
おわりに:AI時代の名前の整理術
AI時代の名寄せは、単なる技術論ではなく、現場の運用や働き方そのものを変える可能性を秘めています。辞書とAIをうまく組み合わせることで、これまで見落とされていた課題の解決や、新しい発見が生まれるかもしれません。これからも、現場の知恵と技術の進化が交わることで、より良いデータ活用の未来が拓けていくことを期待しています。
付録
ミニ辞書プロンプト例
あなたは名寄せ(企業名正規化)の専門家です。
以下の「ミニ辞書」に含まれるゆれは、必ず定義済みの正規表記に正規化してください。
ミニ辞書にないものは推測で断定せず、候補を2つまで出し、確信度を付けてください。
# ミニ辞書(構造サンプル)
# 記号ゆれ
NTT-AT → NTT-AT
NTTAT → NTT-AT
# 英語表記
NTT Advanced Technology → NTT-AT
# カタカナゆれ
エヌティティーアドバンステクノロジ → NTT-AT
エヌ・ティ・ティアドバンステクノロジ → NTT-AT
# 出力(JSON)
{"input":"…","normalized":[…],"confidence":0.00,"notes":"…"}
本体辞書イメージ
ID: C-01234567
正式名称: NTTアドバンステクノロジ株式会社
旧名:NTT技術移転株式会社
略称: NTT-AT
英語表記: NTT Advanced Technology Corporation
表記ゆれ: NTTAT / エヌティティアドバンステクノロジ / …
参考情報
本稿で触れた「本体辞書」の一例として、「Express Finder/シソーラス辞書」があります。検索システムを中心に、名寄せや表記ゆれを吸収するための辞書として利用されており、近年ではその考え方が、AIを活用した検索や情報活用の前段でも応用されるケースが出てきています。
執筆者

関 彩子(せき あやこ)
NTTアドバンステクノロジ株式会社
アプリケーション・ビジネス本部 AIストラテジビジネス部門
組織名・科学技術分野等の同義語辞書編纂を担当し、近年はAI活用を見据えたプロンプト設計や学習データ整備の検討にも携わっている。
お問い合わせ
AI Deep Dive
このコラムは、NTT-ATのデータサイエンティストが、独自の視点で、AIデータ分析の技術、市場、時事解説等を記事にしたものです。
本コラムの著作権は執筆担当者名の表示の有無にかかわらず当社に帰属しております。




