Column
コラム
AIデータ分析コラム【25】音声合成におけるAI活用について
2025.03.04

近年、私たちの生活のあらゆる場面でAIが活用されるようになり、身近なものとなって来ました。
本コラムでは、AI・機械学習・深層学習などの技術の進化によって、より自然で聞き取りやすくなって来た音声合成の技術について紹介します。
音声合成の方式は?
音声合成とは、人間の声を真似た音声を人工的に生成する技術ですが、その歴史は古く、1700年代後半に母音や子音を発する機械が開発されています。人間の声道を模倣したもので、肺代わりであるふいごから音源部に空気を送り込むことで、母音と子音を発声させるものだったようです。
その後、コンピュータの技術が進化し、現在のコンピュータを使った音声合成技術が誕生したのは1950年代と言われています。
音声合成の方式は、録音編集方式とテキスト音声合成方式に分類されます。
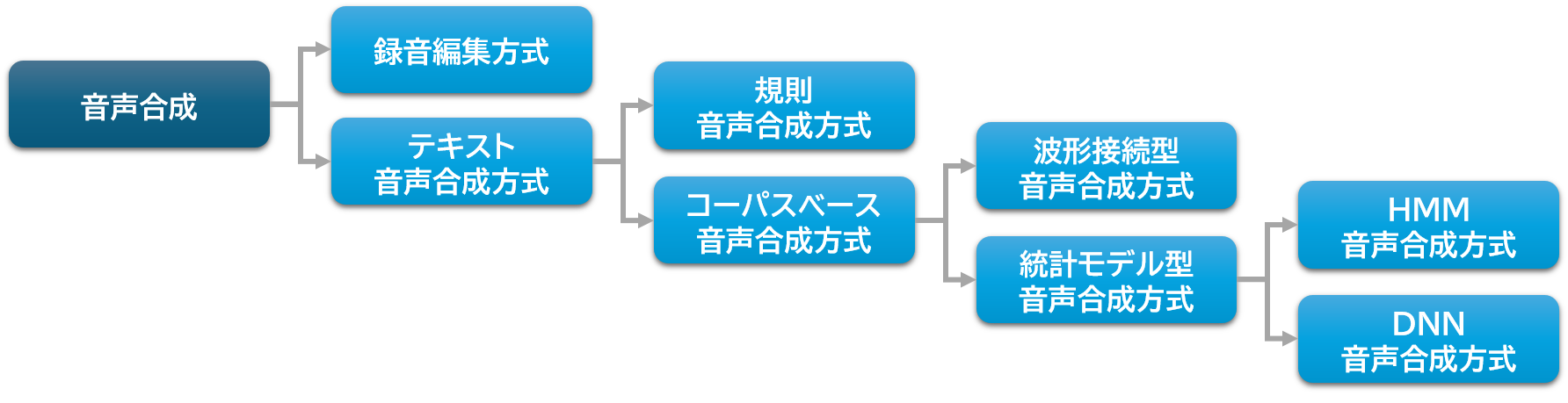
録音編集方式とテキスト音声合成方式
録音編集方式は、単語やフレーズをあらかじめ録音しておき、それらをつなぎ合わせて音声を合成する技術です。読み上げる文章パターンが限定されている駅の構内アナウンスなどに利用されています。読み上げる語彙を追加したりする場合には新たに音声を録音する必要があり、また、不自然に聞こえないように、既存の音声データと同一話者で録音したりする必要があるなどの制約があります。
テキスト音声合成方式は、入力された任意のテキストから音声を合成する技術です。単語より小さい音素や音節などの単位の音声素片を組み合わせて合成するため、任意のテキストに対して音声の合成が可能となります。
テキスト音声合成方式は、規則音声合成方式とコーパスベース音声合成方式に分類されます。
規則音声合成方式とコーパスベース音声合成方式
規則音声合成方式は、音声合成の専門家による音響的・言語的知見に基づいて音声波形を合成する技術です。テキストから音声を生成するため発話内容を自由に変更することが可能ですが、人間らしさに乏しい機械的な音声になってしまう欠点があります。
コーパスベース音声合成方式は、テキストとその発話を集めてデータベース化した音声コーパスを作成し、その中から音声波形を取り出して接続することにより音声を合成する技術です。1990年代以降、コンピュータの処理性能の向上、AI・機械学習・深層学習などの技術の進化に伴い、音声コーパスから抽出した音声波形を用いて音声を合成する、コーパスベース音声合成方式が主流になっています。
コーパスベース音声合成方式は、波形接続型音声合成方式と統計モデル型音声合成方式に分類されます。
波形接続型音声合成方式と統計モデル型音声合成方式
波形接続型音声合成方式は、収録した音声を音素単位に分割して音声コーパスに蓄積し、入力されたテキストの言語解析で得られた音素列、アクセント、構文の情報を元に、最適な音声素片を音声コーパスから抽出して組み合わせて合成する技術です。最適な音素素片が音声コーパスに蓄積されているかによって合成音の品質に影響を与えるため、高品質な音声を合成するためには、大規模な音声コーパスが必要となります。
統計モデル型音声合成方式は、音声コーパスに蓄積した音声波形の音響特徴量とテキストの言語特徴量を機械学習により統計的にモデル化し、入力テキストの言語特徴量に対応する音響特徴量を生成し、それに基づいて音声を合成する技術です。音声を予測して合成するため、波形接続型音声合成方式に比べて比較的少ない音声データ量でも安定した合成が可能であるため、近年は、この手法の利用が急速に進んでいます。
統計モデル型音声合成方式のモデル化の代表的な手法として、隠れマルコフモデル(Hidden Markov Model)を用いたHMM音声合成方式と、ディープニューラルネットワーク(Deep Neural Network)を用いたDNN音声合成方式があります。
HMM音声合成方式とDNN音声合成方式
HMM音声合成方式は、言語特徴量と音響特徴量の関係を決定木に基づくコンテキスト依存HMMによって表現する手法です。決定木に基づいて対応する学習データも分類されてしまうため、より複雑な言語特徴量の違いを表現しようとすると、各コンテキスト依存HMMに割り当てられる学習データが減少してしまい、音質の劣化を招いてしまう問題があります。
DNN音声合成方式は、言語特徴量と音響特徴量の関係をDNNによって表現する手法です。決定木では表現することが困難であった複雑な言語特徴量と音響特徴量の関係を表現することが可能です。決定木に基づいて対応する学習データが分割されて学習データが減少してしまうHMM音声合成方式と異なり、学習データ全体から単一のDNNを学習するため、学習データを効率良く利用することができ、より精度の高い音響特徴量を予測することが可能です。しかし、高品質の音声を合成するためには、学習に膨大な学習データと相応の時間が必要となります。
音声合成サービス
現在、統計モデル型音声合成方式を用いた音声合成サービスが数多く提供されており、音声収録のコストと時間の削減、業務効率化、顧客満足度の向上などの目的で、自社サービスやコンテンツ作成に音声合成を導入する企業が増えています。
クラウドサービスの大手でも音声合成のサービスを提供しており、提供されているAPIを利用することで、音声合成を活用したアプリケーションを自身で作成することができます。
音声合成の活用事例
AI・機械学習・深層学習などの技術の進化に伴い、より自然で聞き取りやすい音声を合成できるようになったことにより、私たちの身近なところで音声合成を耳にする機会が増えて来ています。例えば、
駅構内の案内
防災行政無線
カーナビの音声
ゲームのセリフ
コールセンターのボイスボット
YouTubeなどの動画のナレーション
スマートスピーカー
AIアナウンサー
本の朗読
など、その他にも様々なところで音声合成が活用されていますが、私が注目している活用事例を以下に紹介します。
発話困難者向けのコミュニケーション支援
食道がんや喉頭がんなどの病気で声帯を摘出する手術を控えている方や、ALS(筋萎縮性側索硬化症)やパーキンソン病などにより、今後、発話が困難になる可能性がある方向けの音声合成によるコミュニケーション支援ツールへの活用方法です。
声を失う前の自分の声を録音しておくことで、テキスト入力した情報を自分のAI音声で読み上げたり、発話しづらい音声をAI音声で補正して出力させたりするなどの取り組みが行われています。
本コラム執筆時点では、声帯摘出手術をされる方やALSの方向けに、録音した自分の声を用いたAI音声を無料で提供するサービスも行われているようです。
AIの技術の進化により、以前と比べて少ない収録時間で自分の声に近いAI音声を作成することが可能になって来ましたが、コミュニケーション手段として声を必要としている方に、より自然に聞こえるAI音声をより簡単で気軽に利用できる時代が来ることを期待しています。
アナウンス、ガイダンスなどの多言語変換
日本語で話したアナウンスやガイダンスを音声認識し、英語や中国語、韓国語などの他の言語に変換して音声合成で発話する活用方法です。
日本語を多言語に変換して発話するだけでなく、話者の声質を保ったまま多言語へ変換するサービスもすでに存在しているようです。
近年、日本を訪れる外国人旅行客は急増しており、2024年の年間の訪日外客数は過去最多となっています。 外国人旅行客の困りごとの上位に「施設等のスタッフとのコミュニケーションが取れない」が入っており、旅行先での多言語対応が課題となっています。観光施設に様々な言語を話せるスタッフを配置することは困難であり、また、あらゆる言語に対応したガイダンス音声を事前に録音して準備することは容易ではありません。
今後、外国人旅行客がさらに増加し、それに伴い、多言語対応の需要がさらに高まるため、音声合成技術を活用した多言語変換サービスの活用が加速して行くことが予想されます。
おわりに
本コラムでは、AI技術の進化に伴い、より自然で聞き取りやい音声に進化し続けている音声合成について紹介しました。
音声合成については、有名人の音声データを使って学習したモデルで作成した声を無断で使用したり、実在する人物になりすまして詐欺などに悪用すると言った問題もありますが、それらの問題を解決しつつ、さらに技術が進化して、我々の身近なコミュニケーションの手段として活用されて行くことを期待しています。
執筆者

久保田 哲也(くぼた てつや)
NTTアドバンステクノロジ株式会社
アプリケーション・ビジネス本部 DXビジネス部門
入社以来、研究開発支援を中心としたアプリケーション開発に取り組み、現職では、主にデータ分析にかかわる研究支援に従事している。
お問い合わせ
AIデータ分析コラム
このコラムは、NTT-ATのデータサイエンティストが、独自の視点で、AIデータ分析の技術、市場、時事解説等を記事にしたものです。
本コラムの著作権は執筆担当者名の表示の有無にかかわらず当社に帰属しております。


