Column
コラム
AIデータ分析コラム【18】LLMの最新の動向について
2024.07.02

2017年にGoogleから発表されたTransformerに関する論文を皮切りに、大規模言語モデル(LLM: Large Language Models)の研究が盛んになっています。
2022年11月にOpenAIが有名なLLMの一つであるGPTを用いたチャットボット「ChatGPT」を公開し、大きな話題になりました。NTTでも、2024年の3月に高性能かつ軽量なLLMである「tsuzumi」の商用利用を開始しました。
本稿では、LLMの進化の勢いを調べるために、言語処理のトップカンファレンスに採択された論文から、LLMに関する論文の件数の推移や概要について調査した内容を中心に説明します。
LLMとは
大規模言語モデル(LLM: Large Language Models)とは、その名の通り巨大なデータセットを用いてトレーニングされた言語モデルです。主に自然言語処理の分野で使用されます。
その言語理解能力は人間に近いと言われ、要約や翻訳、推論、プログラムのコーディングサポートなどのタスクを行うことができます。
代表的なLLMとしては、OpenAIの「GPT」、Googleの「BERT」、NTTの「tsuzumi」などが挙げられます。
LLMに関する論文件数の推移
LLMについて、自然言語処理分野のトップカンファレンスではどの程度の件数が取り扱われているのでしょうか。
以下のカンファレンスにおいて、2018年から2023年までのLLMに関する論文件数の推移を調査しました。
▪️ACL
▪️EMNLP
▪️TACL
上記カンファレンスで採択された論文より、”LLM”または”Large Language Model”という単語が概要文(Abstract)に含まれている論文の数をカウント(三単現の”s”は除外し、ケースインセンシティブで判定)すると、以下の結果でした。
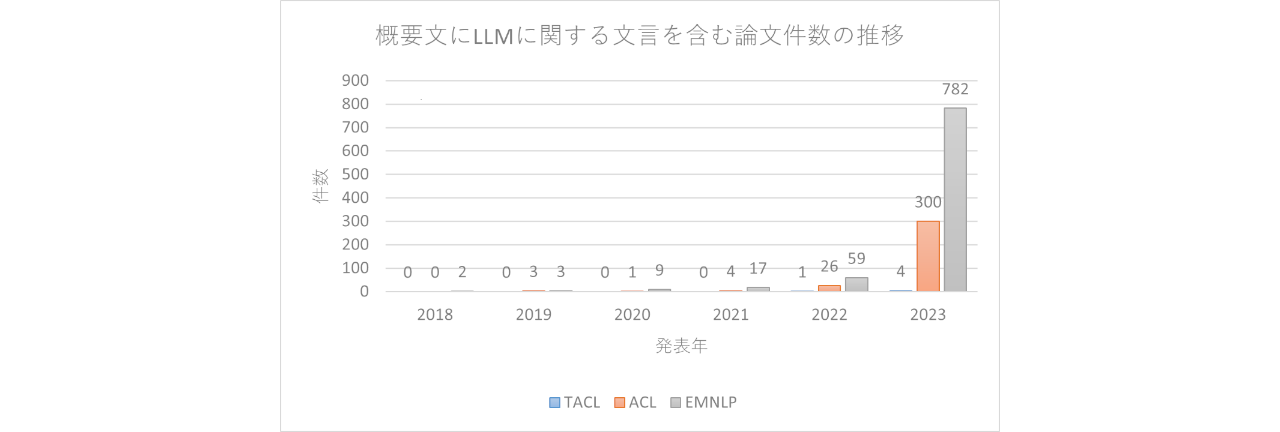
ここで設定した検索条件ではTACLはあまりヒットしませんでした。
ACL、EMNLPでは2022年頃から件数が増え始め、2023年には前年の10倍以上の論文が発表されています。このことから、直近1、2年でLLMに関する研究が爆発的に増えてきたことがわかります。
LLMに関する論文内容
次に、ACLに投稿されたLLMの論文を200個ほどサンプリングして、その概要文を元にどのようなタスク、課題があるのかを調査しました。また、私見ではありますが今後特に注目している分野に関して記載しました。
タスク
LLMで解決しようとするタスクとして、主に以下のようなものが挙げられていました。
1. 推論
2. 対話、質疑応答
3. 翻訳
4. 要約
5. 算術
6. コーディング
1.~4.はLLMでよく取り扱われるタスクです。特に2.は、まるで人間と会話しているかのように自然なやり取りを行うことができることから、最近はLLMを用いたチャットボットが増えてきています。ただし、学習が不十分な話題への応答を行うことはできません。そのため、ACLのある論文では、そのような話題に遭遇した際にLLMが外部の専門家にアクセスして知見を得るというフレームワークを提案しています(このような手法はRAG【Retrieval Augmented Generative】に分類されます)。
5.は単純な足し算や引き算からもう少し複雑な数学の問題までLLMに解かせるというタスクです。ACLのある論文では、数学のような非言語スキルをLLMに学習させることでLLMの中核を担う言語スキルの性能低下が見られ、その原因を解明することが重要であると謳うものがあります。
6.はプログラムのコーディングに関するタスクです。ユーザ(人間)が指定した条件に基づくプログラムの生成のほか、最近では与えられたプログラムの内容解説、リファクタリングまでも行えるなど、急速に発展しているタスクでもあります。ACLのある論文では、プログラム中の関数・サブルーチンの入出力の動作関係を学習し、プログラムの意味をより深く理解する方法を模索するものがあります。こうしたアプローチは特にソフトウェア開発のテスト工程において、テストケースを作成する際に有用になるのではないかと思います。
課題
LLMに対する課題として、主に以下のようなものが挙げられていました。
1. 低コスト化
2. 社会的規範・常識の反映
3. モデル内部に蓄積された情報の保護
1.は特にオンプレミスでLLMを利用・運用しようとする場合に課題となる事柄です。冒頭で述べた通り、LLMは巨大なデータセットを用いてトレーニングされたモデルであることから、そのモデルサイズも巨大であることが多いです。そのため、ACLの論文では、なるべく精度を保ったままモデルサイズを小さくすることを課題として、知識蒸留(必要な知識を小さなサイズのモデルへ伝達する手法)などによって低コスト化を図る研究が見受けられます。
2.はLLMによって生成される内容に国や地域の社会的規範・常識が上手く反映されているか、反映するにはどうすれば良いかという課題です。例えば同じ仕草を表現した文章でも日本と海外では捉えられ方が全く異なるようなケースがあるかもしれません。そうした違いを吸収せずにモデルを運用していると、時にユーザにとって不適切な内容を提供する可能性があります。こうした課題に対してACLの論文では、トレーニングの段階でバイアスの評価を行い、大きくバイアスのかかるデータを削減してリスクを軽減する方法や、知識編集を行い修正する方法があります。
3.はLLMによって生成される文章や画像などが他者のコンテンツの著作権を侵害してしまうリスクに対する課題です。この課題は文化庁でも「AIと著作権に関する考え方について」と題したページを公開するなど、生成AIを扱う上で避けては通れないものとなっています。最終的に侵害有無を判断するのは人間ではありますが、ACLの論文ではウォーターマーク(透かし)を埋め込む手法や、コンテンツの生成起源を追跡できるようにする手法など、最終的な判断のための材料を調達する仕組みが提唱されています。
注目している分野
個人的に特に注目している分野はコーディングです。前述の通り、今回調査したACLの論文の中にはプログラムを解析しその意味を深く理解する方法を模索するものがありました。現在はサポート、リファクタリングを行える程度のレベルですが、こうした方法が発展していくことで、よりクリエィティブな作業を行えるようになることが期待されます。一例としては、webサイトの自動生成が挙げられます。webサイトとして備えてほしい機能・要件・条件を列挙し作成を指示することで、これまでは作成するのに苦労していたようなある程度複雑なwebサイトをその場で簡単に構築できる日が訪れるかもしれません。ただし、これは便利な半面、攻撃に利用される可能性もあるため、扱いには十分なルール作り・制限の設定が必要です。
おわりに
本稿では言語処理のトップカンファレンスの論文概要を元に、LLMに関する論文件数の推移や、そこで扱われているタスク、課題について調査しました。2023年に論文件数が爆発的に増えていたことから、LLMの分野はいま非常にホットな領域であると考えられます。ここ数年でどこまで展開するのか楽しみですね。今後も引き続き注目していきたいと思います。
参考
ACL(Association for Computational Linguistics), https://2023.aclweb.org/,2023年6月参照
EMNLP(Empirical Methods in Natural Language Processing), https://2023.emnlp.org/,2023年6月参照
TACL(Transactions of the Association for Computational Linguistics), https://transacl.org/index.php/tacl,2023年6月参照
執筆者

大島 哲(おおしま さとし)
NTTアドバンステクノロジ株式会社
アプリケーション・ビジネス本部 DXビジネス部門 アドバンスドデータサイエンス担当
大規模分散処理基盤や機械学習を用いたシステムの開発や調査・検証を担当。
現職では、AIを活用したデータ分析のビジネス展開に従事。
お問い合わせ
AIデータ分析コラム
このコラムは、NTT-ATのデータサイエンティストが、独自の視点で、AIデータ分析の技術、市場、時事解説等を記事にしたものです。
本コラムの著作権は執筆担当者名の表示の有無にかかわらず当社に帰属しております。


